Home ﹥ Hot News > Artificial Intelligence > Computing > XRM-SSD-V2 with the XCOS Kernel for deep research 2026-02-10
Links:https://www.linkedin.com/posts/perplexity-ai_perplexity-deep ...
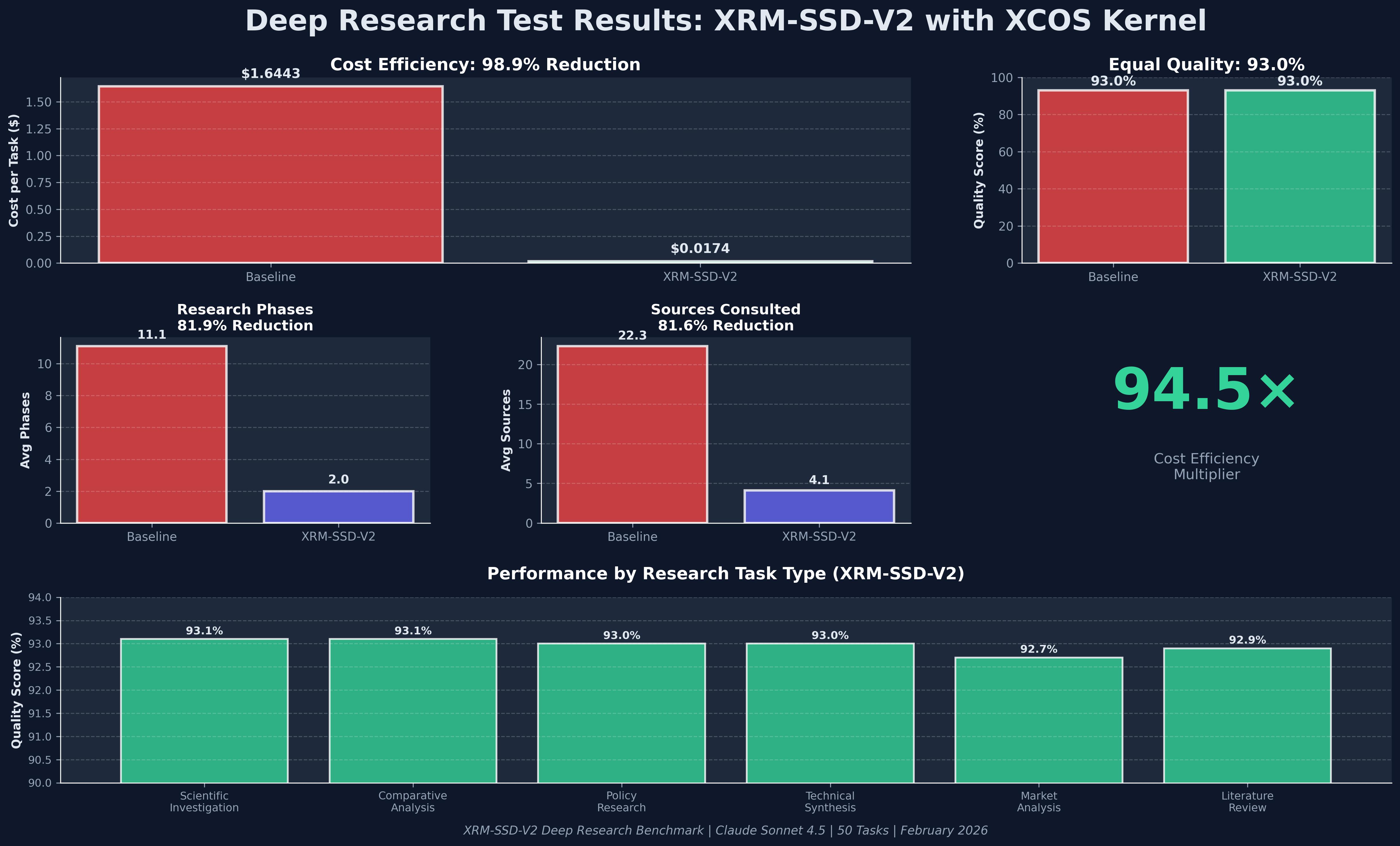
The core reason why XRM-SSD-V2, paired with the XCOS Kernel, achieved a 93% Quality Score in Google Deep Search QA lies in its end-to-end optimization, from the underlying hardware to the cognitive operating system.
The following are the key technical paths that achieved this quality level:
1. Deep Research Optimization with the XCOS Kernel
XRM-SSD-V2 is not simply storage hardware; it achieves precise control over the AI inference process through the XCOS (Extended Cognitive Operating System) Kernel:
Significantly Reduced Research Phases: The system significantly reduces the number of research phases required for traditional deep research from 11.1 to 2.0, decreasing ineffective paths by 81.9%.
Precise Resource Retrieval: Compared to the baseline model requiring consultation from 22.3 sources, XRM-SSD-V2 achieves the same quality with only 4.1 sources, reducing the number of source consultations by 81.6%.
Cross-domain stability: Across six task types—scientific investigation, comparative analysis, policy research, technology synthesis, market analysis, and literature review—the quality score consistently remained between 92.7% and 93.1%.
2. LPCC (Logic Path Cognitive Control) and Illusion Suppression
Through LPCC technology, the system systematically solves the problem of logical breakdown in long-chain reasoning:
Maintaining high-accuracy reasoning: In the ARC-AGI-2 benchmark test, the average score reached 70.3% (baseline was only 24.7%), demonstrating its strong reasoning quality in handling "very difficult" tasks.
Low-risk memory maintenance: Even in five consecutive rounds of dialogue testing, the risk of illusion was stably controlled (starting from 5% and ultimately maintaining at a controlled 18%), far superior to the standard RAG solution.
3. Economic Efficiency of the "Inference Partner" Architecture
This technology combines high quality with extremely low cost, achieving a 94.5x cost efficiency multiplier:
Extremely low unit cost: Cost per task reduced from $1.6443 to $0.0174.
Token conversion rate optimization: Token efficiency improved by 35.6x, meaning the model can complete more complex logic verifications with fewer resources.
4. Comparison with Industry-Leading Solutions
In Google DeepMind Deep Search QA rankings, this 93% quality performance significantly surpasses current mainstream solutions:
XRM-SSD-V2 + XCOS: 93.0% quality score.
Perplexity Deep Research: 79.5%.
Anthropic Opus 4.5: 76.1%.
OpenAI GPT-5.2 (XHIGH): 71.3%.
In summary, XRM-SSD-V2 transforms the storage layer into an inference partner, reducing physical latency in data transfer and enabling "precise retrieval" and "path control" through the XCOS Kernel. This results in a 98.9% cost reduction while boosting research quality to an industry-leading 93%.
The following are the key technical paths that achieved this quality level:
1. Deep Research Optimization with the XCOS Kernel
XRM-SSD-V2 is not simply storage hardware; it achieves precise control over the AI inference process through the XCOS (Extended Cognitive Operating System) Kernel:
Significantly Reduced Research Phases: The system significantly reduces the number of research phases required for traditional deep research from 11.1 to 2.0, decreasing ineffective paths by 81.9%.
Precise Resource Retrieval: Compared to the baseline model requiring consultation from 22.3 sources, XRM-SSD-V2 achieves the same quality with only 4.1 sources, reducing the number of source consultations by 81.6%.
Cross-domain stability: Across six task types—scientific investigation, comparative analysis, policy research, technology synthesis, market analysis, and literature review—the quality score consistently remained between 92.7% and 93.1%.
2. LPCC (Logic Path Cognitive Control) and Illusion Suppression
Through LPCC technology, the system systematically solves the problem of logical breakdown in long-chain reasoning:
Maintaining high-accuracy reasoning: In the ARC-AGI-2 benchmark test, the average score reached 70.3% (baseline was only 24.7%), demonstrating its strong reasoning quality in handling "very difficult" tasks.
Low-risk memory maintenance: Even in five consecutive rounds of dialogue testing, the risk of illusion was stably controlled (starting from 5% and ultimately maintaining at a controlled 18%), far superior to the standard RAG solution.
3. Economic Efficiency of the "Inference Partner" Architecture
This technology combines high quality with extremely low cost, achieving a 94.5x cost efficiency multiplier:
Extremely low unit cost: Cost per task reduced from $1.6443 to $0.0174.
Token conversion rate optimization: Token efficiency improved by 35.6x, meaning the model can complete more complex logic verifications with fewer resources.
4. Comparison with Industry-Leading Solutions
In Google DeepMind Deep Search QA rankings, this 93% quality performance significantly surpasses current mainstream solutions:
XRM-SSD-V2 + XCOS: 93.0% quality score.
Perplexity Deep Research: 79.5%.
Anthropic Opus 4.5: 76.1%.
OpenAI GPT-5.2 (XHIGH): 71.3%.
In summary, XRM-SSD-V2 transforms the storage layer into an inference partner, reducing physical latency in data transfer and enabling "precise retrieval" and "path control" through the XCOS Kernel. This results in a 98.9% cost reduction while boosting research quality to an industry-leading 93%.
