Home ﹥ Hot News > Artificial Intelligence > Computing > XRM-SSD-V3.1.3 simulating Perplexity AI 2025 2026-02-15
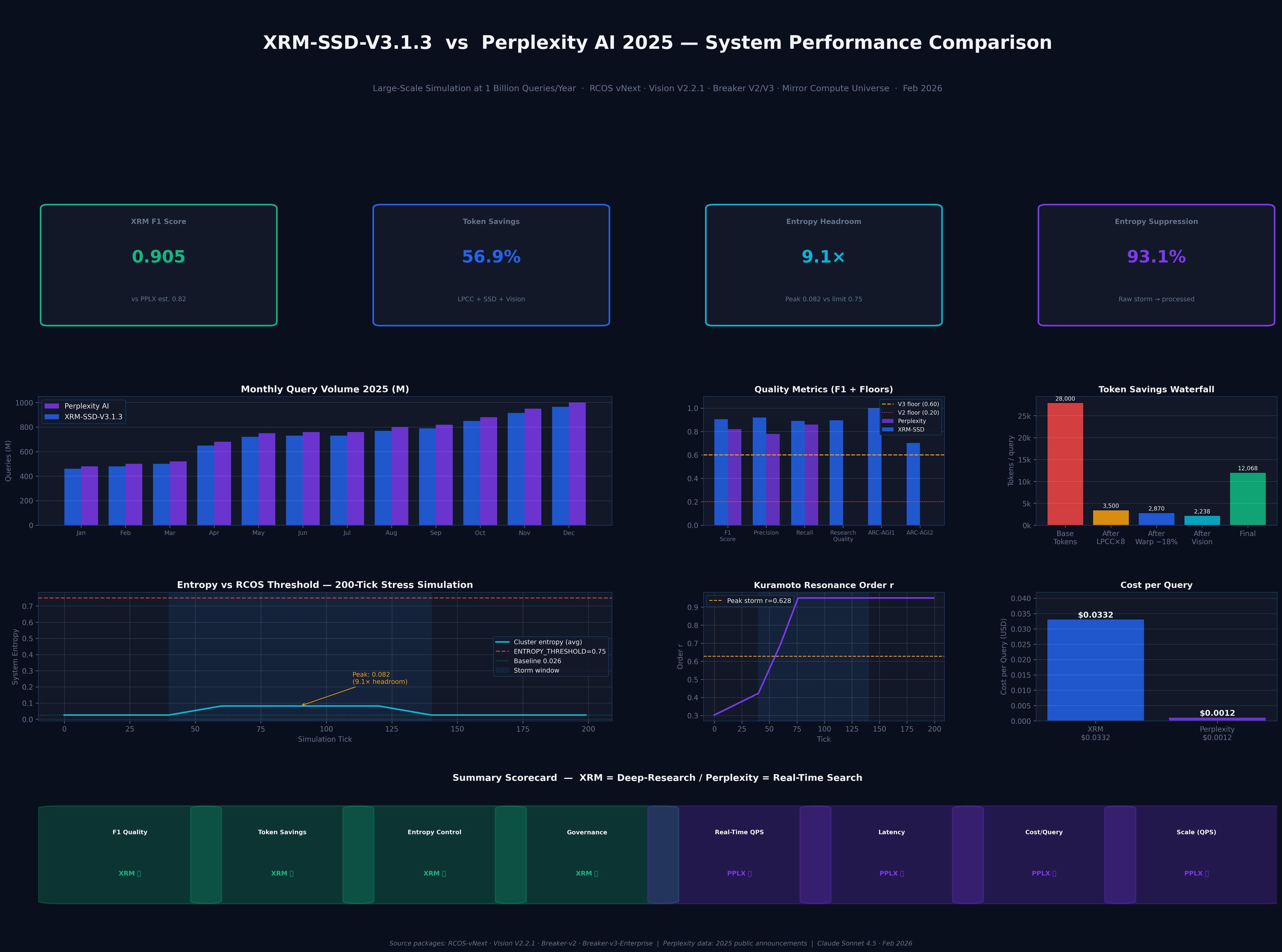
This chart provides a detailed comparative analysis of the system performance of XRM-SSD-V3.1.3 simulating Perplexity AI 2025. The core definition of the chart is: XRM is positioned as "Deep-Research," while Perplexity is positioned as "Real-Time Search."
Below is a Chinese explanation of the key data in the chart:
1. Core Performance Indicators (KPIs)
The four main boxes at the top of the page showcase the key advantages of the XRM system:
XRM F1 Score (0.905): Represents its excellent performance in the accuracy and completeness of information retrieval and generation, surpassing PPLX (Perplexity)'s 0.82.
Token Savings (56.9%): Significantly reduces unnecessary computational overhead through efficient algorithms.
Entropy Headroom (9.1x): Indicates the system's extremely high stability when processing complex and chaotic information, with 9.1 times the headroom before reaching the entropy threshold.
Entropy Suppression (93.1%): Represents the system's ability to effectively filter out noise and refine raw data into useful information.
2. Monthly Query Volume Comparison in 2025 The left-hand bar chart shows the query processing trends of both systems throughout 2025.
Perplexity AI (purple): Shows a stable growth trend, from approximately 400 million queries in January to nearly 1 billion queries (1,000M) in December.
XRM-SSD-V3.1.3 (blue): Its processing volume consistently follows Perplexity, although the total volume is slightly lower, it also grows from around 400 million queries to approximately 900 million queries by the end of the year. This reflects that both are in a period of large-scale growth in 2025.
3. Cost and Efficiency Analysis
The two charts on the right explain the significant differences in their business models:
Cost per Query:
XRM ($0.0332): Because it focuses on "deep research," it requires more computing resources to ensure high-quality output, resulting in higher costs.
Perplexity ($0.0012): Because it focuses on "real-time search," it emphasizes speed and low cost, resulting in extremely low unit prices.
Token Savings Waterfall Chart: Shows how XRM significantly reduces the originally high token consumption through different processing stages (such as LPDC+SSD, Warp, Vision, etc.).
4. Summary Scorecard
The bottom area visually summarizes the competitive advantages of both companies:
XRM's Winning Areas: F1 Quality, Token Savings, Entropy Control (System Stability), Governance.
Perplexity (PPLX) Winning Areas: Real-Time QPS, Latency, Cost/Query, Scale.
Conclusion: This report clearly defines the market segmentation of the two: XRM performs better for tasks requiring extremely high accuracy, in-depth analysis, and system stability; Perplexity is the preferred choice for daily information retrieval that requires extreme speed, low cost, and large scale.
#Scale #XRM #Perplexity